

以前下記の記事でWebクリップのワークフローを解説しましたが、もう完全にこのフローはぶっ壊れました。
RaindropもNotionもできることが多いというのもあって、良い感じの使い分けに困っており、それが原因でこのワークフローが破綻してしまったのだと思います。
その反省を生かして今回はこの2ヶ月ぐらい上手く行ってるどシンプルなRaindropとNotionだけを使うワークフローを紹介します。
前提: 多くの記事を読む必要はない
以前はRSSリーダーとかを使ってより多くの記事に触れて、多くの記事を読もうと思ってたのですが意味がないと気づきました。
ニュース記事は毎日読んだところで大して自分の能力向上には繋がらないので、インプットの目的を「自己能力の向上」と捉えるなら効率の悪い行為になります。
個人的なコンテンツの質として
ニュース記事 < 個人ブログ記事 < 良質なメディア記事 < 本
だと思っているので、限られた時間でインプット時間を捻出するなら本を読むのがベストだと言えます。
ただ、毎回インプットの時間があるからといって読書をするメンタリティ、モチベーションの人はいないでしょう。(よっぽどの読書の変態でない限り)
なので、読みたい・読む必要のある記事というのをRaindropなり何らかのアプリでストックしておき、読書以外のインプットの選択肢を常に持っておく必要があると考えています。
Raindropを使わないことで起こる問題
でも記事をストックしておこうと思って、Twitterとかで良さそうな記事を見つけると、とりあえずChromeの新しいタブで開いて「後で読もー」って放置してませんか?
そんな感じの「後で読もー記事」が大量に残ってタブ多すぎストレス問題になってませんか?
これ私です。
Pocketとかブックマークツールを使ったことないのでわかりませんが、この問題を解決することを目的にRaindropの運用方法を考えました。
RaindropとNotionの役割
前回の記事では
- Raindrop: 永久保存
- Notion: お気に入りのWebメディアを保存
という形式で運用していましたが、現在はざっくり
- Raindrop: 後で読む記事・お気に入りのメディアなどを保存
- Notion: 永久保存
という形に変更しています。
インプットのフローを簡略化
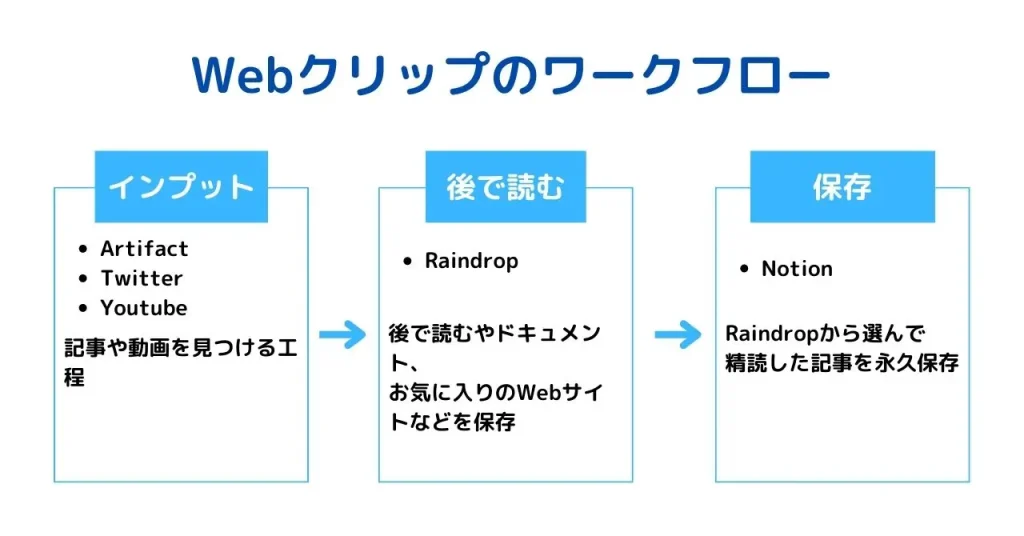
まず、インプットのフローをかなりシンプルにしました。
前回はInoreaderで毎日大量の記事に目を通して、良いものはRaindropに保存して、Twitterやなんかで良いメディアを見つけたらNotionのWebサイトDBに保存する….というめんどくさいフローを作って満足していました。
今回はざっくり、後で読むものはRaindrop、読み終わって永久保存したいものはNotionと完全に住み分けしたのでインプットの際にフローを考える必要がなくなりました。
Randropのコレクション構成
総じて『後で読む記事』を保存していきますが、「Twitterで見つけた面白そうな個人ブログの記事」や「本の代わりになるような骨太の解説記事」など粒度はまちまちです。
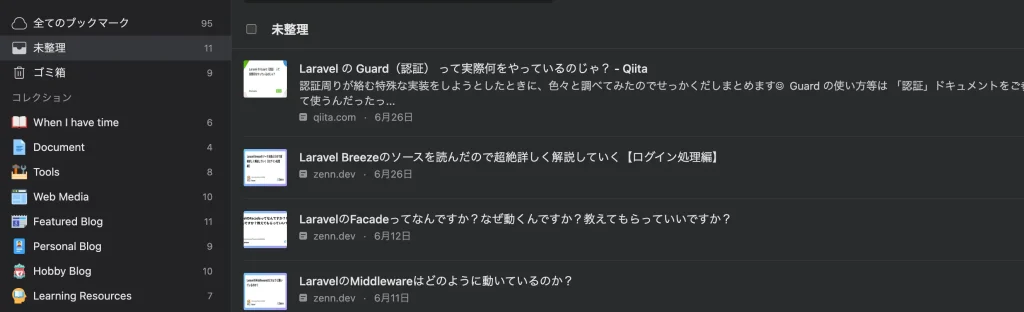
使い方として、コレクション構成は以下のようにしており、タグは使っていません。
- Unsorted(未整理)
- When I have time(時間があるときにじっくり読む)
- Document(公式ドキュメントなど)
- Tools(便利なWebサービス)
- Web Media(お気に入りのビジネスメディア)
- Hobby(お気に入りの趣味メディア)
RaindropでURLを入力すると自動的に[Unsorted(未整理)]コレクションに入ってくれるので「後で読む記事」はここで管理していきます。
[When I have time(時間があるときにじっくり読む)]コレクションでは後で読もうと思うんだけど優先順位が低いもの、例えば現在はLaravelを学習しているけど将来的に学びたいDockerで話題の記事などがここに入ってきます。
[Document]コレクションはそのままでLaravel公式や日本語ドキュメントなど各言語やFW、体系化されたマニュアルが入ります。
[Tools]コレクションには便利なWebサービスが入ります。例えばバフェット・コードやThe 社史などを自分は入れています。
[Web Media]、[Hobby]についてはそのままで好きなWebメディア(例えばアプリマーケティング研究所)、好きなスポーツなどのメディア(THE COACHES’ VOICE JAPANなど)を入れています。
場合によってはさらに細分化しても良いですが、ここ2ヶ月ぐらいはこの6つのコレクションでうまくいっております。
NotionのDB構成
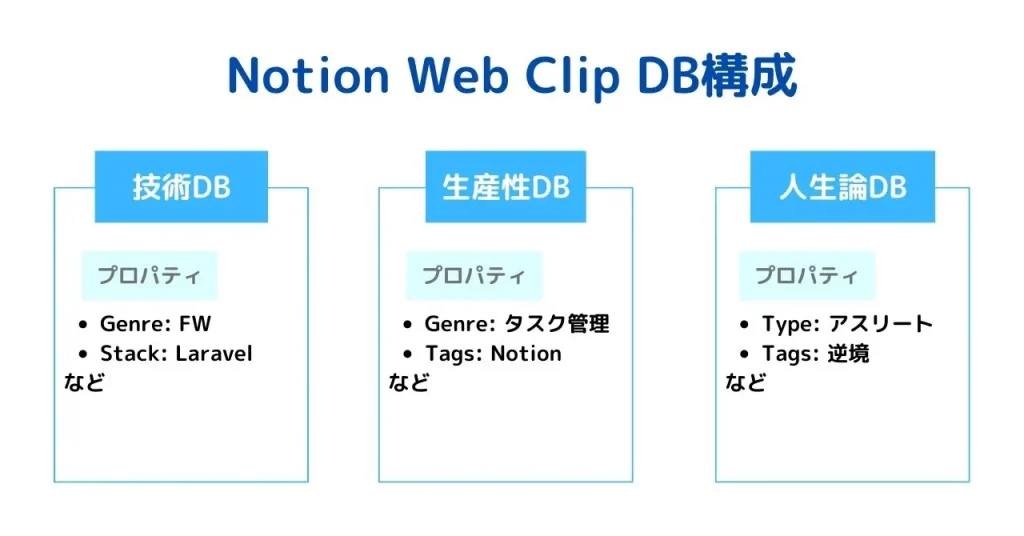
こうして無事読み終わった記事をNotionに保存するか否か判定します。
一つ保存の仕方として工夫した点として「DBを分離させる」ということを行いました。
以前はNotionに『WebクリップDB』という全ての記事を保存する巨大なDBを一つ用意していましたが、現在は各カテゴリーごとにそれぞれDBを作り、データの肥大化を避けるようにしています。
これによってカテゴリーやタグなどプロパティの設定もさらに細分化したものを設定できますし、各DBのデータ量が減るので単純に検索性が上がります。
Raindrop → Notionの流れ
ここまで紹介したインプットからWebクリップまでの例をステップ形式で一つ紹介しておきます。
- 通勤電車でTwitterをいじっている時に良さげな「タスク管理」についての記事を見つける
- すぐに読めそうなのでRaindropに追加し、[Unsorted(未整理)]コレクションに入れておく
- 帰りの電車で疲れたので本を読む気にはなれず、さっき見つけた記事を読むことに決める
- Raindropに行って、[Unsorted(未整理)]コレクションから先ほどの「タスク管理」についての記事をクリックし読む
- めちゃくちゃ良かったので永久保存すると決める
- Notionの[Productivity Articles DB(生産性記事のデータベース)]に保存
- 週末にNotionからその記事を再度開いて、実際にやってみる
まとめ: 厳選して記事を保存していくということ
Raindropで「後で読む記事」を選択するときも、Notionで「永久保存する」と選択するときも厳選するということを自分は重視しています。
エンジニアならドキュメントは一通り読んでおくべきだし、本も積読はしているし、Youtubeの解説動画も見なきゃだし、購入したUdemyの講座も進めなきゃだし、サブスクしている有料メディアの記事も読まないといけない。
そんな中であれもこれも[後で読む]としているとどんどん記事が溜まり、その分知らんうちに「まだこんな読まなきゃいけない記事がある…」とストレスが溜まります。
精読して、自分の言葉でまとめたり、読み返したりすることでインプットが「自己能力の向上」につながってくれるので、まずは『読むべき記事の数を減らすこと』その次に『読んだ中でも後世に残したいと思うレベルの記事のみを保存すること』。
この2つを注意すれば良いインプットライフを送れるのではないでしょうか。
noteでも情報発信中
noteではより広く「AI時代の人生戦略」「男磨き」という領域でDoberというブランド名で発信しています。私個人の人生戦略や進捗、Threadsで伸びたコンテンツの深掘りなどを行っているのでぜひチェックいただけると!
最新情報はXやThreadsで発信しているので、そちらもフォローしてもらえると嬉しいです!刻式垢でフォローいただければ発信されている方はフォロバします!仲良くしてください!









コメント